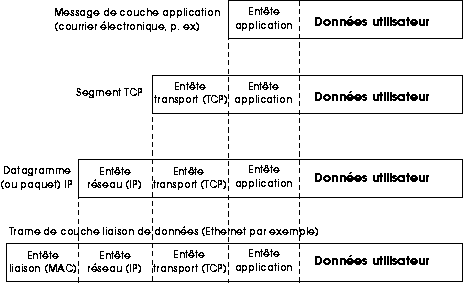
L'Internet est un réseau virtuel, construit par
interconnexion de réseaux physiques via des passerelles. Cette partie
parle de l'adressage, le maillon essentiel des protocoles TCP/IP pour
rendre transparents les détails physiques des réseaux et faire apparaître
l'internet comme une entité homogène.
Unicité de l'adresse:
Un système de communication doit pouvoir permettre à n'importe quel
hôte de se mettre en relation avec n'importe quel autre. Afin qu'il n'y
ait pas d'ambiguïté pour la reconnaissance des hôtes possibles, il est
absolument nécessaire d'admettre un principe général d'identification.
Lorsque l'on veut établir une communication, il est intuitivement
indispensable de posséder trois informations :
- Le nom de la machine distante.
- Son adresse.
- La route à suivre pour y parvenir.
Le nom dit "
qui '' est l'hôte distant, l'adresse nous dit "
où '' il se
trouve et la route "
comment '' on y parvient.
En règle générale les utilisateurs préfèrent des noms
symboliques
pour identifier les machines tandis que les processeurs de ces
mêmes machines
ne comprennent que les nombres exprimés au format binaire.
Les adresses IP (version 4) sont standardisées sous forme d'un
nombre de
32 bits qui permet à la fois l'identification de chaque hôte
et du réseau auquel il appartient. Le choix des nombres composants une
adresse IP n'est pas laissé au hasard, au contraire il fait l'objet
d'une attention particulière notamment pour faciliter les opérations de
routage.
Chaque adresse IP contient donc deux informations élémentaires, une
adresse de réseau(NetId) et une
adresse d'hôte(
HostId). La combinaison des deux désigne
de manière unique une machine et une seule sur l'Internet, sous réserve
que cette adresse ait été attribuée par un organisme ayant pouvoir
de le faire !
Délivrance des adresses IPv4:
On distingue deux types d'adresses IP :
- Les adresses privées
- que tout
administrateur de réseau peut s'attribuer librement pourvu qu'il(elle)
ne cherche pas à les router sur l'Internet
- les adresses publiques
- délivrées par une structure mondiale qui
en assure l'unicité. Ce dernier point est capital pour assurer
l'efficience du routage.
Les adresses à utiliser sur les
réseaux privés sont décrites par la RFC 1918 :
10.0.0.0 |
10.255.255.255 |
172.16.0.0 |
172.31.255.255 |
192.168.0.0 |
192.168.255.255 |
Les adresses publiques (souvent une seule), sont le plus généralement
fournies par le FAI
. Qu'elles soient
délivrées de manière temporaire ou attribuées pour le long terme, elles
doivent être uniques sur le réseau. La question est donc de savoir
de qui le FAI les obtient.
C'est L'
ICANN ( Internet Corporation for Assigned Names and
Numbers
) qui est chargé au niveau
mondial de la gestion de l'espace d'adressage IP. Il définit les
procédures d'attribution et de résolution de conflits dans l'attribution
des adresses, mais délègue le détail de la gestion de ces ressources à
des instances régionales puis locales, dans chaque pays, appelées
RIR (Regional Internet Registries ).
Il y a actuellement cinq ( Regional Internet Registries ) opérationnels :
1- APNIC
pour la région Asie-Pacifique.
2- ARIN
pour l'Amérique.
3- RIPE NCC
pour l'Europe.
4- AfriNIC
pour l'Afrique .
5- LACNIC
pour l'Amérique Latine.
Anatomie d'une adresse IP:
Une adresse IP est un nombre de 32 bits que l'on a coutume de
représenter sous forme de quatre entiers de huit bits, séparés par des
points .
La partie réseau de l'adresse IP vient toujours en tête, la partie
hôte est donc toujours en queue.
L'intérêt de cette représentation est immédiat quand on sait que la
partie réseau et donc la partie hôte sont presque toujours codées sur
un nombre entier d'octets. Ainsi, on a principalement les trois formes
suivantes :
- Classe A
- Un octet réseau, trois octets d'hôtes.
- Classe B
- Deux octets réseau, deux octets d'hôtes.
- Classe C
- Trois octets réseau, un octet d'hôte.
Décomposition en classes:
figure 1 -- Décomposition en classes
Pour distinguer les classes A, B, C, D et E il faut examiner
les bits de poids fort de l'octet de poids fort :
Si le premier bit est 0, l'adresse est de classe A. On
dispose de 7 bits pour identifier le réseau et de 24 bits pour
identifier l'hôte. On a donc les réseaux de 1 à 127 et 2
24
hôtes possibles, c'est à dire 16 777 216 machines différentes
(de 0 à 16 777 215).
Les lecteurs attentifs auront remarqué que le réseau 0 n'est pas
utilisé, il a une signification particulière ( tous les
réseaux ) .
De même, la machine 0 n'est pas utilisée, tout comme la machine
ayant le plus fort numéro dans le réseau (tous les bits de la
partie hôte à 1, ici 16 777 215), ce qui réduit de deux unités
le nombre des machines nommables. Il reste donc seulement
16 777 214 machines adressables dans une classe A !
- Si les deux premiers bits sont 10
- l'adresse est de classe B.
Il reste 14 bits pour identifier le réseau et 16 bits pour
identifier la machine. Ce qui fait
214= 16 384 réseaux
(
128.0 à 191.255) et 65 534 (65 536 - 2) machines.
- Si les trois premiers bits sont 110
- l'adresse est de classe
C. Il reste 21 bits pour identifier le réseau et 8 bits pour
identifier la machine. Ce qui fait
221=2 097 152 réseaux
(de
192.0.0 à 223.255.255) et 254 (256 - 2) machines.
- Si les quatres premiers bits de l'adresse sont 1110
- il s'agit
d'une classe d'adressage spéciale, la classe D. Cette classe est
prévue pour faire du multicast , ou multipoint. (RFC 1112 ), contrairement aux trois premières classes qui
sont dédiées à l'unicast ou point à point.
Ces adresses forment une catégorie à part, nous en reparlons
au paragraphe.
- Si les quatres premiers bits de l'adresse sont 1111
- il s'agit
d'une classe expérimentale, la classe E. La RFC 1700 précise " Class E addresses are reserved for future use " mais
n'indique pas de quel futur il s'agit...
Enfin, pour conclure , calculons le nombre d'hôtes adressables
théoriquement à l'aide des classes A, B et C : 127 x 16777212 + 16384 x 65534 + 2097152 x 254 = 3737091588
Ce total, pour être plus exact, doit être amputé des 17 890 780 hôtes
des réseaux privés prévus dans la RFC 1918
, soit donc
tout de même au total
3 719 200 808 hôtes adressables en utilisant IPv4 !
Sous-réseaux:
Les
avantages de la segmentation en sous-réseau sont les suivants :
1. Utilisation de plusieurs media (câbles, supports physiques). La
connexion de tous les noeuds à un seul support de réseau peut s'avérer
impossible, difficile ou coûteuse lorsque les noeuds sont trop éloignés les uns
des autres ou qu'ils sont déjà connectés à un autre media.
2. Réduction de l'encombrement. Le trafic entre les noeuds répartis sur
un réseau unique utilise la largeur de bande du réseau. Par conséquent, plus
les noeuds sont nombreux, plus la largeur de bande requise est importante. La
répartition des noeuds sur des réseaux séparés permet de réduire le nombre de
noeuds par réseau. Si les noeuds d'un réseau de petite taille communiquent
principalement avec d'autres noeuds du même réseau, l'encombrement global est
réduit.
3. Economise les temps de calcul. Les diffusions (paquet adressé à tous)
sur un réseau obligent chacun des noeuds du réseau à réagir avant de l'accepter
ou de la rejeter.
4. Isolation d'un réseau. La division d'un grand réseau en
plusieurs réseaux de taille inférieure permet de limiter l'impact d'éventuelles
défaillances sur le réseau concerné. Il peut s'agir d'une erreur matérielle du
réseau (une connexion
5. Renforcement de la sécurité. Sur un support de diffusion du réseau
comme Ethernet, tous les noeuds ont accès aux paquets envoyés sur ce réseau. Si
le trafic sensible n'est autorisé que sur un réseau, les autres hôtes du réseau
n'y ont pas accès.
6. Optimisation de l'espace réservé à une
adresse IP. Si un
numéro de réseau de classe A ou B vous est assigné et que vous disposez de
plusieurs petits réseaux physiques, vous pouvez répartir l'espace de l'adresse
IP en multiples sous-réseaux IP et les assigner à des réseaux physiques
spécifiques. Cette méthode permet d'éviter l'utilisation de numéros de réseau
IP supplémentaires pour chaque réseau physique.
Il existe cependant des règles à suivre concernant la création et l’utilisation de sous-réseaux. Ces règles sont régies par les RFC 950 (règle du 2n-2) et RFC 1878 (règles du 2n-1 et du 2n) :
• Règle du
2^n - 2 ==> impossible d’utiliser le premier sous-réseau ainsi que le dernier sous-réseau
• Règle du
2^n - 1 ==>impossible d’utiliser le premier sous-réseau
• Règle du
2^n ==> utilisation de tous les sous-réseaux
L’utilisation d’une de ces règles par rapport à une autre dépend uniquement des capacités techniques des équipements. De nos jours la majorité des réseaux utilisent la règle du 2n puisqu’elle permet de limiter au maximum le gaspillage d’adresses IP.
CIDR:
En 1992 la moitié des classes B étaient allouées, et si le rythme
avait continué, au début de 1994 il n'y aurait plus eu de classe B
disponible et l'Internet aurait bien pu mourrir par asphyxie ! De plus
la croissance du nombre de réseaux se traduisait par un usage "aux limites '' des routeurs, proches de la saturation car non
prévus au départ pour un tel volume de routes (voir les RFC 1518 et
RFC 1519).
Deux considérations qui ont conduit l'IETF a mettre en place
le "Classless InterDomain Routing '' ou CIDR ou encore routage Internet
sans classe, basé sur une constatation de simple bon sens :
- S'il est courant de rencontrer
une organisation ayant plus de 254 hôtes, il est moins courant
d'en rencontrer une de plus de quelques milliers.
Les adresses allouées sont donc des classes C contigües, attribuées
par région ou par continent. En générale, 8 à 16 classes C mises bout
à bout suffisent pour une entreprise. Ces blocs de numéros
sont souvent appellés "supernet ''.
Ainsi par exemple il est courant d'entendre les administrateurs de
réseaux parler d'un " slash 22 '' (/22) pour désigner un bloc
de quatre classes C consécutives...
- Il est plus facile de prévoir une table de routage pour un
bloc de réseaux contigües que d'avoir à le faire pour une
multitude de routes individuelles. En plus cette opération
allège la longueur des tables.
Plus précisement, trois caractéristiques sont requises pour pouvoir
utiliser ce concept :
- Pour être réunies dans une même route, des adresses IP multiples
doivent avoir les mêmes bits de poids fort (seuls les bits
de poids plus faible diffèrent)de poids faibles diffèrent.
- Les tables de routages et algorithmes doivent prendre en compte
un masque de 32 bits, à appliquer sur les adresses.
- Les protocoles de routage doivent ajouter un masque 32 bits pour
chaque adresse IP (Cet ajout double le volume d'informations)
transmise. OSPF, IS-IS, RIP-2, BGP-4 le font.
Ce masque se manifeste concrêtement comme dans la reécriture
du tableau du paragraphe :
| 10.0.0.0 |
10.255.255.255 |
10/8 |
| 172.16.0.0 |
172.31.255.255 |
172.16/12 |
| 192.168.0.0 |
192.168.255.255 |
192.168/16 |
Le terme "classless '' vient de ce fait, le routage n'est plus
basé uniquement sur la partie réseau des adresses.
Les agrégations d'adresses sont ventilées selon le tableau
suivant
:
| Multirégionales: |
192.0.0.0 |
193.255.255.255 |
| Europe: |
194.0.0.0 |
195.255.255.255 |
| Autres: |
196.0.0.0 |
197.255.255.255 |
| Amérique du Nord: |
198.0.0.0 |
199.255.255.255 |
|
|
|
| Amérique du Sud: |
200.0.0.0 |
201.255.255.255 |
| Zone Pacifique: |
202.0.0.0 |
203.255.255.255 |
| Autres: |
204.0.0.0 |
205.255.255.255 |
| Autres: |
206.0.0.0 |
207.255.255.255 |